Experimenting with new (to me) ways of using AI.
Intro
Museum Shuffle was the first app I ever made. I began working on it way back in 2017. I’m still really proud of it but it stopped being a priority for me years ago. I started to get freaked out by the fact that I was pouring so much time into an app that relied 100% on an API that I had no guarantee would be around forever. If that went away the app was mostly useless. Ironically I now focus on an app that is 100% reliant on a single API, but that is another story for another time.
This is the story of how that dependency became an issue and how I fixed it.
It’s Broken
My mom has always been my best beta tester. Realizing that Museum Shuffle had some very broken user interface elements with her larger text is what got me started on caring so deeply about accessibility support. Recently she gave me a phone call and told me that she went to use Museum Shuffle and got this error message:
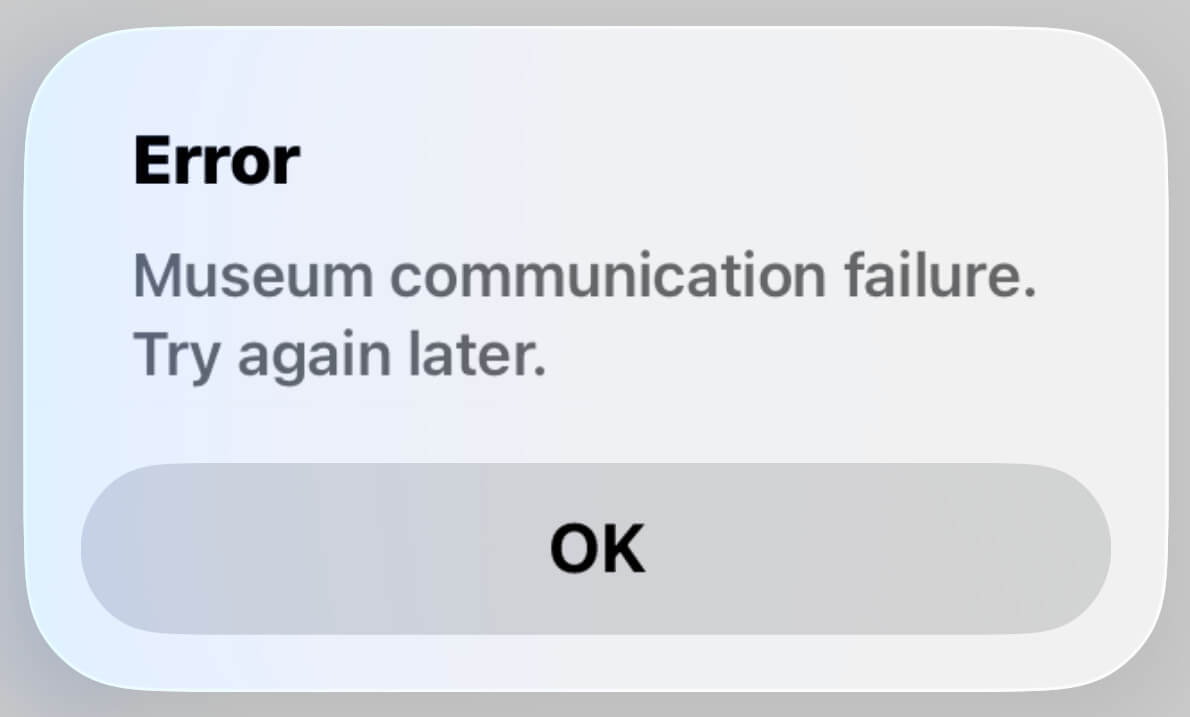
At first I just shrugged it off because an outage for an API isn’t exactly something that’s unexpected. But as the hours and then days went by I started to get a sickening feeling that something was terribly wrong.
Several years ago Mathijs Bernson reached out to me. He works at Q42, the company that develops the Rijksmuseum website, API and apps. He was so nice and had some really kind things to say about the app. I contacted him and he verified that the service was running as expected but dropped a very important piece of information. The API I was using was now considered legacy and had been replaced with a different API. I had absolutely no idea that had happened. The only thing I can figure is that when they sent an email alerting us that this was going to happen that it went to my spam folder, got accidentally deleted by me, or wasn’t sent to me at all.
So the core functionality of the app was completely broken. All you could do was view your previously saved favorite artwork.
New API
When I went and looked at the details of the new API implementation my heart sank. The replacement was very different from what I was using.
Old Way
- Response is standard JSON.
- The response contained all the metadata (title, artist, image URL, etc) for all pieces of artwork returned for the search combination.
- The number of pages of possible results were also returned and you could ask for any of those pages in future shuffles.
New Way
- Responses conform to the following, none of which I had ever heard of before:
- JSON-LD - JSON for Linked Data
- Linked Art - Designed for describing museum/cultural heritage objects via JSON-LD.
- OAI-PMH - Open Archives Initiative Protocol for Metadata Harvesting (uses XML).
- Initial response only contains a list of numeric IDs for each piece of artwork (no metadata) returned for the search combination.
- One call is now needed per artwork to look up the metadata for that artwork. BUT the image URL is no longer included in this metadata.
- Claude figured out it could use the same numeric ID to look up the image URL by parsing for it in the XML response if you also make an OAI-PMH call.
- Page tokens are used instead of page numbers and you can’t just jump to a page by specifying a page number.
It was going to be a massive amount of work to understand and experiment with this new API in order to do a conversion. While Museum Shuffle holds a lot of sentimental value to me I’m not sure that I would have been willing to dedicate a large amount of time to bring it back to life, especially when it would be to the detriment of other things that need my attention. There’s a very good chance I would have pulled it from the App Store.
But these are different times that we’re living in now and I had an option that I wouldn’t have in the past.
Claude Code Makes An Attempt
I wanted to see what Claude Code could do with this effort. I put it into plan mode, gave it a description of the problem we were facing, and a link to the documentation for the new API. It asked me several questions and then got to work.
It was pretty fascinating watching it experiment with the API before it started making changes. It used those results to decide how it would approach the code. The first pass of code changes ended up making 768 insertions and 474 deletions.
It was pretty exciting to see that the first attempt did work pretty well. However, there were a large percentage of the results that did not have an image for the artwork. That’s completely normal once in a while but this was way too many failures to be acceptable.
I had Claude put debug statements in several places to help investigate this issue. Honestly this is one of my favorite parts about working with AI. Manually adding these trace message is an example of a tedious task that I could do in my sleep but I can just let the AI take care of.
The issue ended up being that some artwork is returned with the image URL being the base path. Just adding the default path, name, and extension when this happens fixed this issue. This also gave me a chance to improve what the UI looks like when an image can’t be loaded for an individual piece of artwork.
Century Search Is Broken
Museum Shuffle gives you the ability to specify search parameters and in doing some testing I realized that Claude had completely broken the Picker logic that lets you select a century. It was quick work for it to fix it though. The problem was that the old API let you specify a number, such as 17, for a century. But for the new API a wild card was being used. For example, 16??, and the question marks were being encoded incorrectly for URLQueryItem.
Claude was actually really helpful with improving the century search. First of all, it made me realize I had a silly error in that I let the user pick the 22nd century, which is in the future.
I also had a nagging issue with early centuries. In the extremely early centuries almost all of the artwork categories would return no results, which I worried would be confusing. I was able to have Claude do several queries to the API and give me an understanding of how much artwork and how many categories of artwork were being returned for the early centuries. That made it much more clear to decide when I should just cap the starting century at. I certainly could have done these queries myself by hand but it would have been slow and tedious to get back the results I got in seconds.
Shuffling Algorithm Suspicions
I studied how Claude changed the shuffling algorithm used and got suspicious that there was a scenario where certain artwork could appear but then wouldn’t appear again in later shuffles. With the old API the initial shuffle for a search combination returns how many pages of results there were for that particular search combination. Then in consequent shuffles for that same combination I could randomly pick a page to randomly pick artwork from. But the new API doesn’t let you specify page numbers. Instead you have to specify a particular token for a particular day.
It turns out I was right to be suspicious. What Claude was doing with the new API was retrieving the first page of results and the token for the next page. The next shuffle would use the next page of results using that token and put it in a token cache. But page 1 would actually never get visited again because it wouldn’t have an entry in the cache of tokens. So I had Claude correct that as well.
We’re Done
And with that we were done. The full functionality of the app had been restored. In this Bluesky post I wasn’t exaggerating when I said that it would have taken me weeks to do all this work in the time I have available.
The deprecated Rijksmuseum API that Museum Shuffle used is very different from its replacement.
I’m 100% certain that it would have taken me weeks to adapt to it in my little free time I’d devote to it.
I did it in a few hours with Claude Code. 🤯
— Chris Wu 🪐 (@chriswu.com) February 14, 2026 at 9:31 AM
[image or embed]
These certainly are interesting times that we are living in!
Good Practice
Writing this blog post actually gave me good practice in something I haven’t been doing, which is using Claude to dig into my Git history. That was so helpful with refreshing my memory on details about this whole effort.
And it was good practice with writing because I wrote this without any AI assitance. 😉 (with the exception of the new API details)
Contact
If this post was helpful to you I’d love to hear about it! I’m @chriswu.com on Bluesky and @MuseumShuffle@mastodon.social on Mastodon and my email is museumshuffle at gmail dot com.