Using some of my favorite tools to create translation files for my SwiftUI app.
Something that’s been long overdue is for me to learn about Internationalization and localization. As I was watching a Hacking With Swift Plus video to learn about them I immediately raised an eyebrow when I saw the format of the localizable strings file. This would be perfect for the awk command!

I feel that it’s important for me to point out that in this blog post (and all of my other blog posts) I’m not suggesting that the steps I’m taking are necessarily the best way to do things. I’m not suggesting they’re the only way to do things. I’m just learning and experimenting in public.
In my SwiftUI app I use an array of strings that populates a Picker that lets the user choose what to search for. This particular array is for specifying the material that will be searched for.

Transforming a file with Vim
I want each word to be on its own line. You could accomplish this is many ways, including with sed. I’m really used to editing and creating text in Vim so that’s what I’m using. As you can probably guess I’m thrilled that Vim commands were added to Xcode 13. I put the text into a file in the standalone Vim application on my Mac and ran the following command.

Let’s break down what this means. We want to start at line 1 and then extend to the end of the file (the dollar sign indicates that). You could replace dollar sign to have this only happen from the top of the file to a certain line. The ’s’ means we’re going to substitute. What we’re searching for is between the slashes. We’re going replace every instance of a comma followed by a space. What do we replace that with? I want to replace that as if we had hit the return key to make a new line. You can’t just hit the return key when entering this command because Vim would think that would mean we were done entering the command! In our Vim substitution you get around this by hitting control-v and then the key (return in this case). It prints out as ^M, which is a little confusing. The ‘g’ means this is a global (whole file) substitution.
With that one command each string is now on its own line.
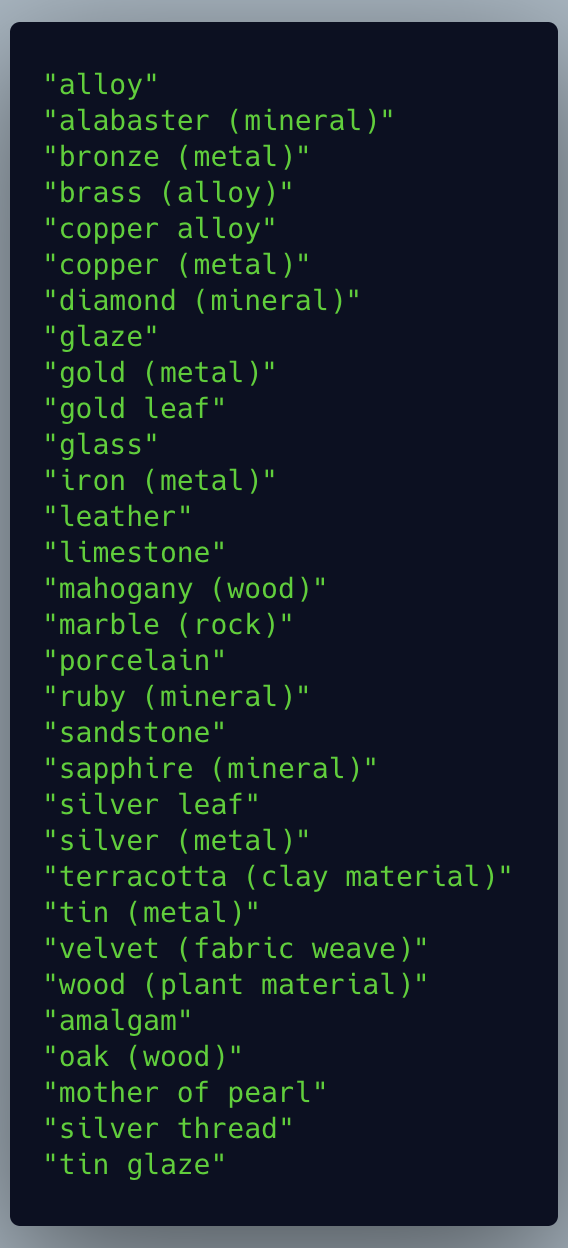
It takes just one line of awk to put this into the expected format of the translation files.
Producing output with awk

In its basic form awk takes a “pattern” and then where there’s a match it performs an “action” that is between curly braces. Here there is no pattern so it performs the action on each line. Strings we want to print are between double quotes. That’s how we’re printing the equals sign and semicolon with the correct spacing.
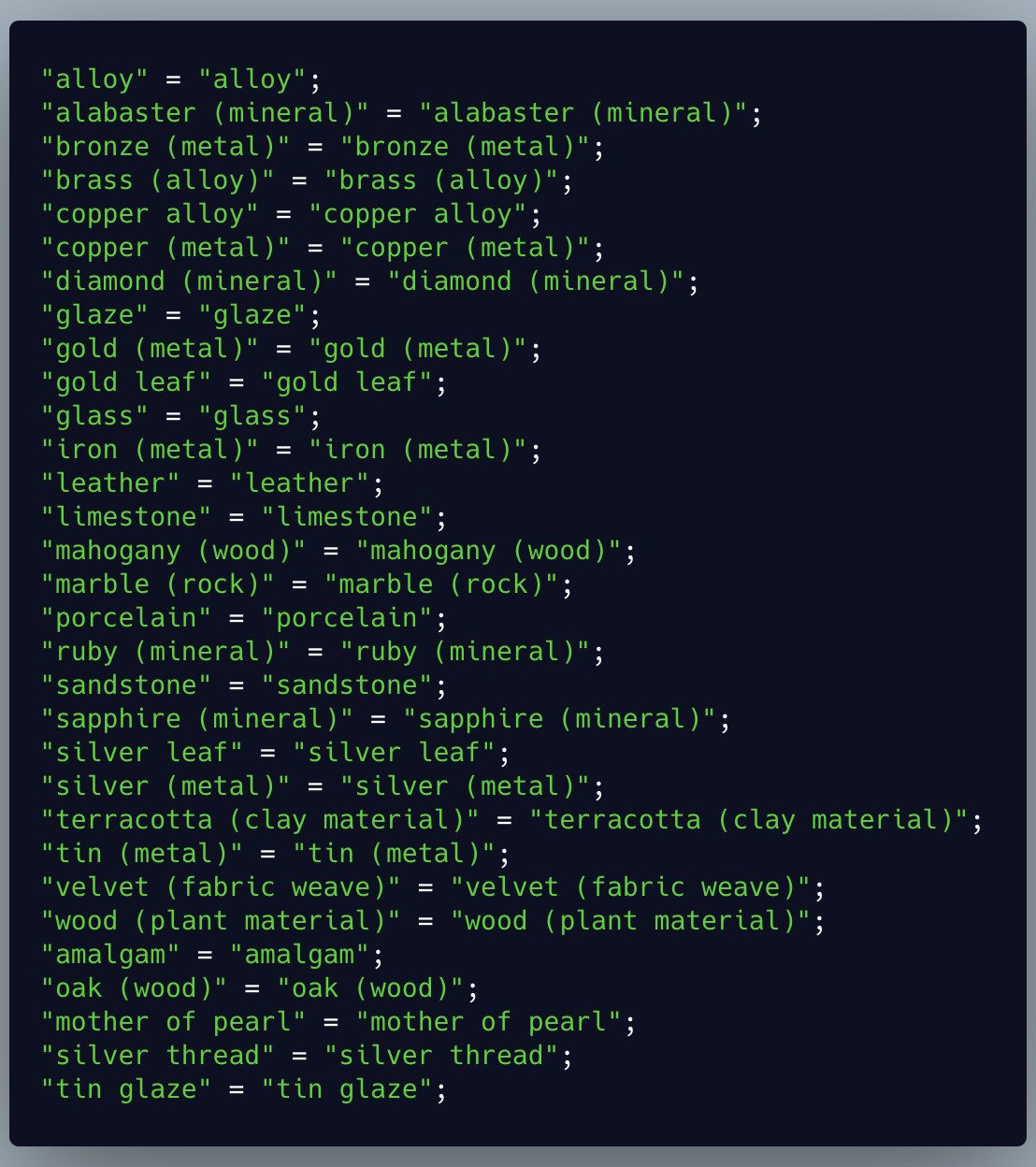
I was curious if my original list of strings could be fed into Google Translate to translate all of them into Dutch. I was pleased to discover that worked!

So I loaded these results into another file and used the same method with Vim to make each result be on its own line. Now I’ve got two files with the same number of lines and each line in each file corresponds to the other. How to we parse both of these files and produce output in the format the translation files expect? That can be done with one line of awk also!

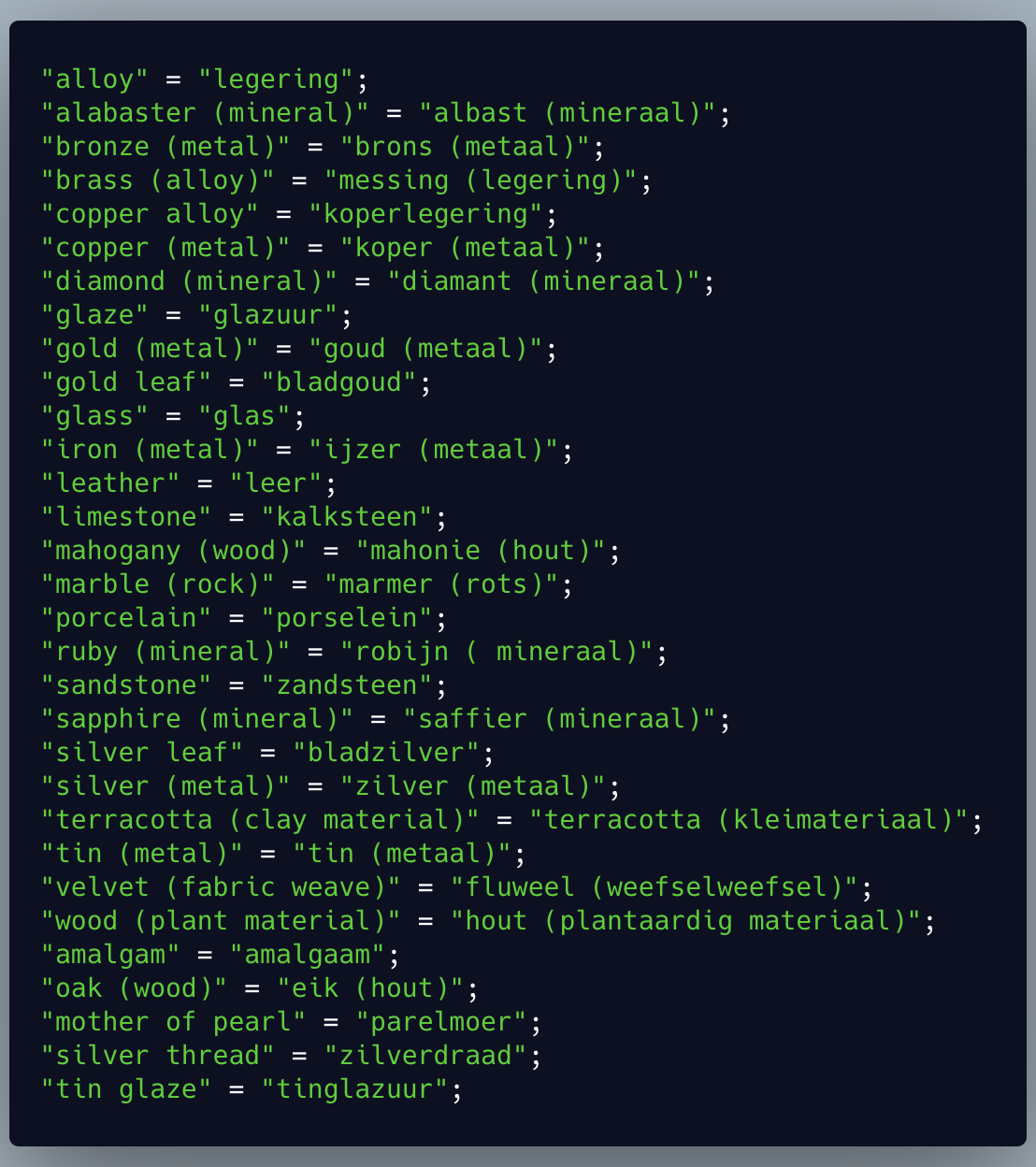
This looks like a nightmare at first but you can break it down to understand what is happening. awk is going to process two input files one at a time. The first pattern it is looking for is NR==FNR. NR is the total number of records (lines) that we’ve processed so far and FNR is the record (line) number we’re processing in this file. So that means this pattern can only be true when we’re processing the first file. For each line of the first file it’s going to populate an array called “a” using the line number as an index with the contents of that line. It will then hit the “next”, which means awk won’t do any more pattern/action logic for this line because it’s going to move on to the next line. Once awk starts processing the second file NR retains its value but FNR starts over. That means the pattern NR==FNR will no longer produce a match. The next part of the awk command is an action with no pattern, which means it will always be executed for each line. Using the array we created it prints out the contents of the first line of the first file along with the contents of the line it is currently reading from the second file ($0). It keeps repeating this until we have the output we wanted! The English version is on the left and the Dutch version is on the right in the format expected for the translation files.
Wrap up
I still regret that I rolled by eyes and thought “I will never use this” when my favorite college professor taught us awk. I wish I could tell him how much I still use it. Rest in peace Dr. Jones.
Don’t think that you have to be a robot that remembers complex syntax to use awk. There are much simpler examples where awk is still so handy. I remember the concepts of awk but I have to look up syntax almost every time I use it. Heck, I use git almost every day and have to look up how to revert the last commit with changes retained!
If this post was helpful to you I’d love to hear about it! Find me on Twitter.
Carbon
All of the images in this post were created with Carbon. It’s a great tool for sharing code or text.